Adobe Dreamweaver CC 2017で文字コードが誤認されるときの裏技
今年から仕事で使ってるアドビ製品がAbobeCCになりました。ドリームウィーバーもCC(2017)になった訳ですが、最悪に困ったバグが度々発生します。それは・・・
文字コードを誤判定すること。EUC-JPのファイルなのにSJISで開かれる、UTF-8のファイルも何故かSJISで開かれ盛大に日本語が文字化けするトラブル。
ただし全てのファイルが文字化けするわけでなくて法則があります。それはPHPファイルでHTMLのヘッダ情報(厳密にはCharset情報)が無いとき文字化けします。
一般的にこの手のエディタって「内部の文字コードをプログラムが判断」するものなはず。ドリームウィーバー以外にもQXエディタ・EmEditor・NotePad など併用してますが、いずれも文字コード判別ロジックは100点でないにせよ95点くらい。フリー、もしくは安いシャアウエアのこれらのエディタでも95点なのに、技術力なしのアドビが作る超高価なドリームウィーバーの文字コード判別能力は30点くらいですw
ドリームウィーバーCC文字化けの例
以下が文字化けする例
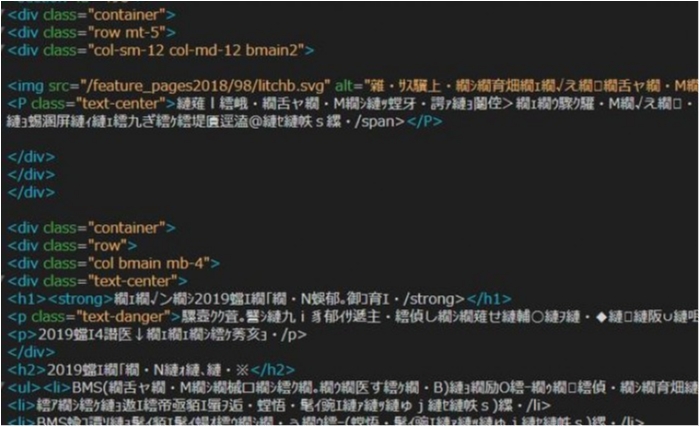
このファイルは別の親PHPファイル達からインクルードされる孫ファイル。よってこのファイル自体にHTMLのヘッダ情報はありません。
内部コードはUTF-8。
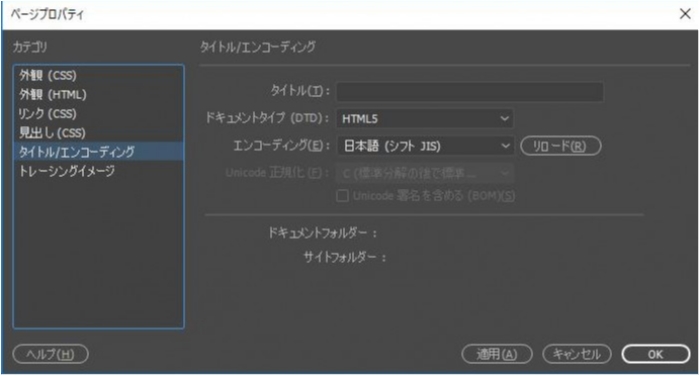
だけどドリームウィーバーでこれを開くとSJISだと判別され盛大に文字化けします。
もう一つの例は以下のファイル。
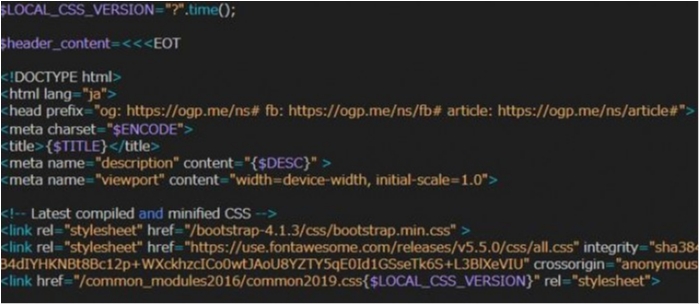
↑上図に日本語部分はないけど下の方の日本語が盛大に化けています。このファイル自体はEUC-JPですが、これを開くとドリームウィーバーはSJISと認識します。
このファイル、大規模サイトのヘッダ部分なので、昨日文字化けに気づかず(日本語部分が画面のはるか下なので)FTPでアップしちゃってサイト全体のレイアウトが総崩れする騒ぎに(笑)
ドリームウィーバーはcharsetの部分で文字コードを判別してる
以上2つの例でピンと来た方も多いと思います。そうなんです、結局ドリームウィーバーCCはそのファイルの中にあるHTMLのCharaset情報を頼りに文字コードを判別してるようなのです。2番めの例では って指定してます。
って指定してます。
先に挙げたテキストエディタはHTMLエディタじゃないから必死に内部的に文字コードを判別するけど、ドリームウィーバーCC様はHTMLエディタであることにあぐらをかいて、charset情報を頼りに文字コードを認識するって訳ですね。ま、ブラウザもそうなので、あんまり責めるのもアレですが、開発者はいろんな書き方をするわけなので、もうちょっとマシな文字コード判別ロジックを内蔵してほしいです。なお、私はDreamweaver自体発売当初から愛用しています。去年まではバージョン8を10年以上使ってましたが、このような文字コード誤判定はほぼ無かったです。ドリームウィーバーCCにしてから急増しました(´・ω・`)
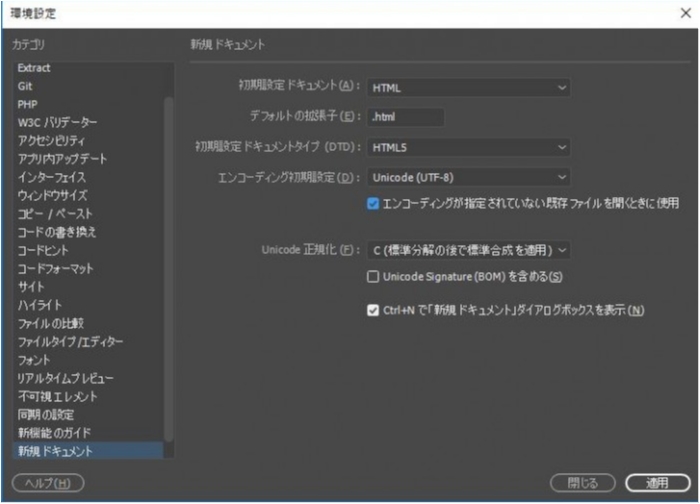
↑ちなみに環境設定でデフォルトのエンコードをUTF-8にしてるのに、なぜかドリームウィーバーCCは「うーーん文字コード判別できないからSJISでいいや」っていう処理をするようです。何のためのデフォルトエンコード設定なんだろう( ゚д゚)
※本国アドビ社の技術力が低いというより日本市場が舐められるor日本のアドビ社開発チーム(あるのか知らん)がダメなだけのような気もしますが・・・
ドリームウィーバーCCの文字コード誤認識をなくす裏技
で、ようやく本題です。以上のように内部的にcharsetを読んで判断してるようなので、そこを突けば問題解決です。
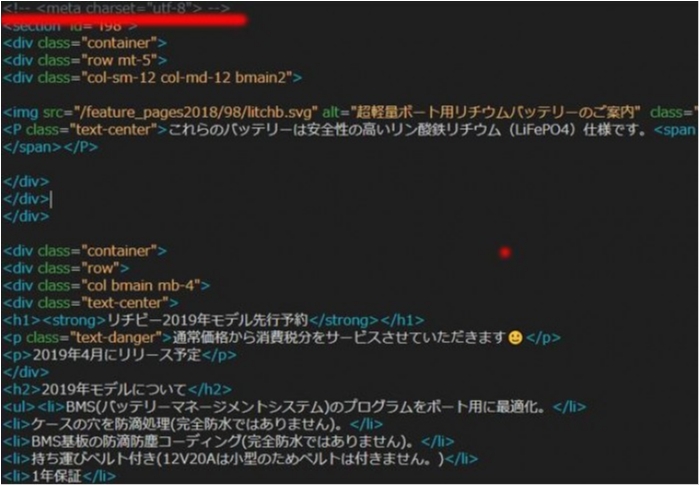
上図のようにHTMLコメントとしてPHPファイルに

という感じで、それぞれの文字コードを指定したmeta charsetをHTMLコメント挿入したら見事に文字化けが解消されました(*´ω`*)
ドリームウィーバーCCでの文字コード誤判定に悩んでる方はお試しください。
なお、この方法も100%完璧じゃないようで98%くらい。meta charsetを挿入する位置に依っては失敗することも・・・。できるだけファイルの冒頭に入れるか、HTMLのヘッダ位置近くに入れると成功率がUPする感じです。
カテゴリ:PC・スマホ・WEBネタ